

The 5 Sources of External Product Expertise for Subscription Apps (and When Each One Fits)
A subscription app crosses $1 million in monthly recurring revenue (MRR). It has an in-house product manager (PM), maybe a growth lead, possibly a designer. But the next leg of growth — paywall optimisation, lifecycle retention modelling, instrumentation auditing, A/B testing infrastructure that compounds rather than churns — sits in the gap between what one PM can carry and what the business now needs to do in parallel.
The procurement question usually lands as a binary: hire another senior in-house specialist, or engage outside help? For most mid-market subscription teams, that binary is already resolved — the hybrid model wins by Series A and B. The harder, less-discussed question is which kind of external expertise fits which problem.
What follows: the 5 sources of external product expertise mid-market subscription apps draw on, what each is structurally good for, where each one breaks, and why one underappreciated dimension — cross-client pattern recognition — compounds in ways no single in-house team can replicate.
The mid-market expertise gap — why in-house teams hit a ceiling
At pre-product-market-fit scale, one founder-led PM can carry the whole product organisation because the work is convergent: find a hypothesis, ship a version, read the dashboard, iterate. At mid-market scale, the work diverges. Paywall optimisation, monetisation modelling, lifecycle retention, instrumentation auditing, A/B testing infrastructure — these aren't four versions of the same discipline. They're four specialisations, each with their own toolchain, benchmark literature, and failure modes.
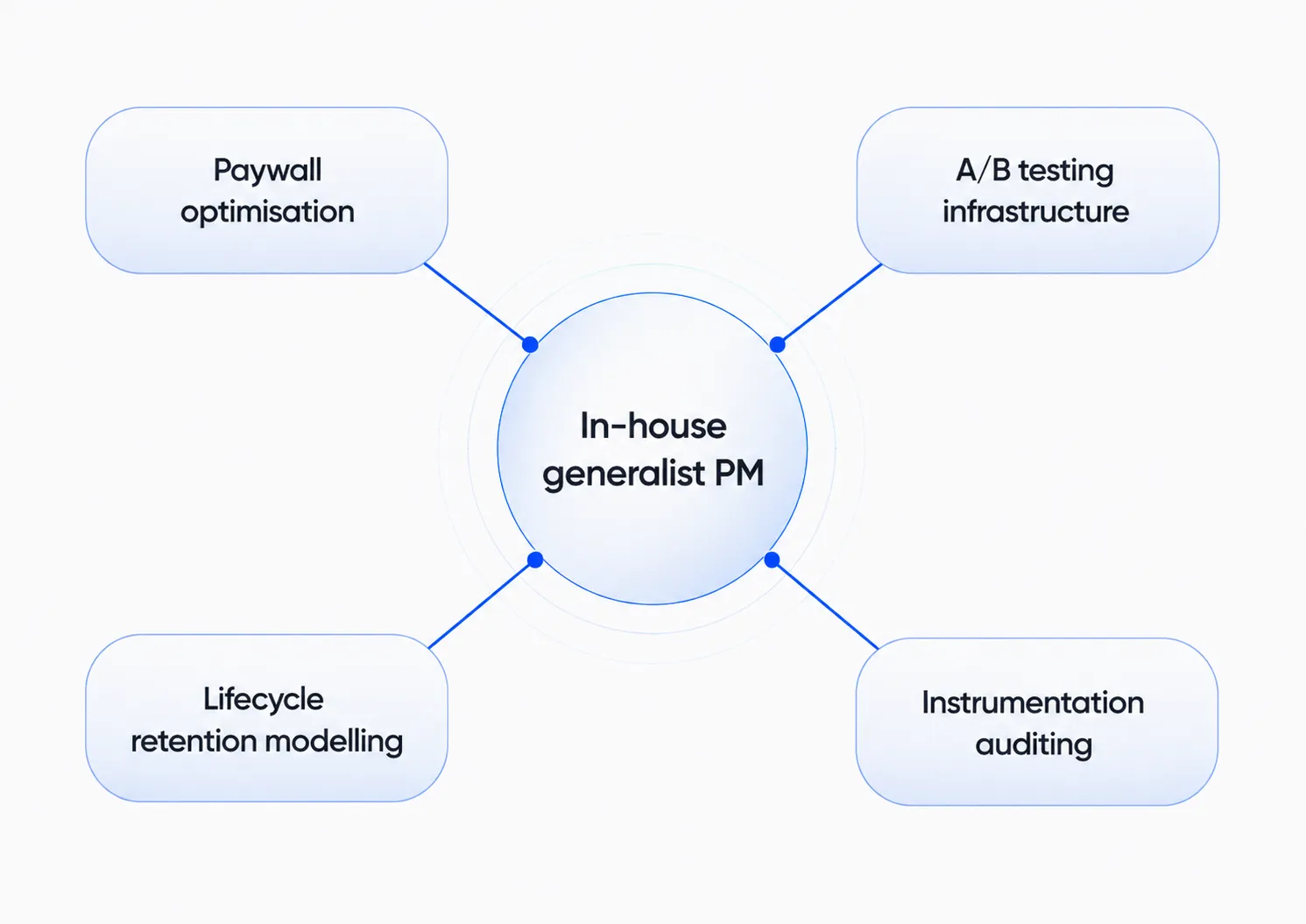
No $1–$10 million MRR app has the headcount budget to hire one specialist per discipline. So the in-house PM, by structural necessity, is a generalist with depth in maybe one of the four — while the work the business now needs is specialist by structural necessity. Both statements are true at once. That's the shape of the gap.
The benchmark data on what the gap costs is unambiguous. RevenueCat's 2026 State of Subscription Apps reports a median MRR growth of 5.3% year-on-year — barely keeping pace with inflation. The top 10% grew 306% or more; the bottom 10% shrank sharply. Only 4.6% of subscription apps reach $10,000 MRR within two years, and most apps hit an organic growth ceiling around $10,000 MRR before paid acquisition becomes structurally necessary. At $1 million-plus MRR the question isn't whether to fill the specialist gap — it's where the expertise comes from to fill it. For the upstream decision on when an in-house Product Growth Manager becomes the right hire, our companion piece covers it.
Where do mid-market subscription teams source product expertise?
5 archetypes show up consistently in mid-market procurement conversations, and they aren't interchangeable. The differences are structural — what each source is built to deliver, what it can't deliver, and what the engagement economics look like.
| Source | Best for | Typical cost | Engagement length | Structural limitation |
|---|---|---|---|---|
| Advisors | Light-touch strategic input, network access, periodic decision sounding-board | Equity 0.1–1% (median 0.13–0.25%) OR $250–$1,500/hour cash | Indefinite, light-touch | No execution capacity, no team |
| Fractional CPOs | Part-time embedded executive-level leadership, cross-portfolio priors | $15,000–$25,000/month | 6–12+ months, 10–25 hrs/week | Scope ceiling on hands-on specialist work; executive-time pricing |
| Cohort courses & workshops | Building internal team capability over time | $1,500–$2,500/seat per course | 4–6 week cohorts | Doesn't solve immediate execution gap; capability per seat |
| Freelance product specialists | Deep execution on one surface, defined scope | Monthly retainer, varies by seniority | Project-bound (weeks to months) | No cross-functional team; narrow scope by design |
| Specialist mobile product growth agencies | Full functional coverage plus cross-client patterns | $8,000–$15,000/month retainer | 6–12+ months | Less institutional context than in-house hire; retainer compounds |
Advisors are equity-compensated subject-matter experts who provide periodic strategic input and network access without hands-on involvement. The 2026 benchmark for advisor equity grants sits between 0.1% and 1% (median 0.13–0.25%, vesting over one to two years), occasionally supplemented by cash retainers in the $250–$1,500/hour range — or hybrid models combining a modest cash retainer with reduced equity at growth stage. They weigh in monthly, make introductions, sanity-check decisions — they don't run the testing programme.
Fractional CPOs embed part-time into the leadership team to drive product strategy and oversee execution. LinkedIn profiles referencing fractional leadership grew from roughly 2,000 in 2022 to over 110,000 by early 2024, and around 30% of startups and mid-sized firms now engage fractional executives in some capacity. Engagements typically span 10–25 hours per week at retainers of $10,000–$25,000/month, against a full-time Chief Product Officer (CPO) cost of $350,000–$700,000+ annually fully loaded.
Cohort courses and workshops — Reforge, Maven, Lenny's, Product Faculty — build internal team capability through practitioner-led programmes. Reforge's 6-week cohorts at roughly $1,995–$2,495/year sit alongside a similar Maven landscape, with Lenny Rachitsky's curated list anchoring how senior PMs continue to upskill across the ecosystem. The category reshaped in March 2026 when Reforge was acquired by Miro, though Learning continues to operate independently.
Freelance product specialists — senior PMs working solo on a defined scope — deliver deep execution on one surface within weeks to months. Right call when the scope is narrow and the hypothesis is sharp.
Specialist mobile product growth agencies — Applica Agency's category — carry full functional coverage across product, design, analytics, paid user acquisition (UA), and creative, with cross-client pattern access built into the operating model. The dimension that compounds differently than any of the others above is what we'll unpack next.
What each source is genuinely good for — and what it can't deliver
The trade-offs aren't symmetric. Each source is built for a specific shape of problem and breaks in a specific shape of context.
Advisors earn their place when the team needs strategic input and network access at modest cost — fundraising-stage decisions, category-specific introductions. They break when execution is the actual bottleneck. The 2026 distinction from a consultant or fractional executive is that advisors offer lightweight strategic support rather than scoped accountability for outcomes.
Fractional CPOs earn their place when the gap is executive-level direction — roadmap, prioritisation, cross-functional alignment, board communication. They break when the work is direct specialist execution at scale; executive-time pricing makes 40 hours of hands-on paywall A/B testing structurally expensive. TechCXO's own framing names the scope precisely: fractional CPOs replace product leadership constraints, not specialist execution constraints.
Cohort courses earn their place when the team has time to build capability on an 18–24 month horizon and the specialists who'll absorb the training are already hired. They break when the immediate need is execution this quarter. A six-week Reforge cohort produces a more capable PM at the end of the cohort — not a paywall lift before then.
Freelance product specialists earn their place when the scope is narrow and the hypothesis is sharp. They break when the bottleneck spans multiple surfaces — no cross-functional team to coordinate paywall, onboarding, retention, and analytics in parallel. One freelancer on one surface produces a real lift; one freelancer on four surfaces produces motion without compounding.
Specialist mobile product growth agencies earn their place when the bottleneck is multi-surface and cross-client patterns compress the diagnostic phase. They break — honestly — on institutional context. An agency operating across 20-plus engagements knows less about your specific product after 30 days than a senior in-house PM does after 18 months. The agency-versus-in-house tension is structural and well-documented: in-house teams have depth of context; agencies have breadth of pattern access. Neither replaces the other.
Why does cross-client experience matter for subscription app growth?
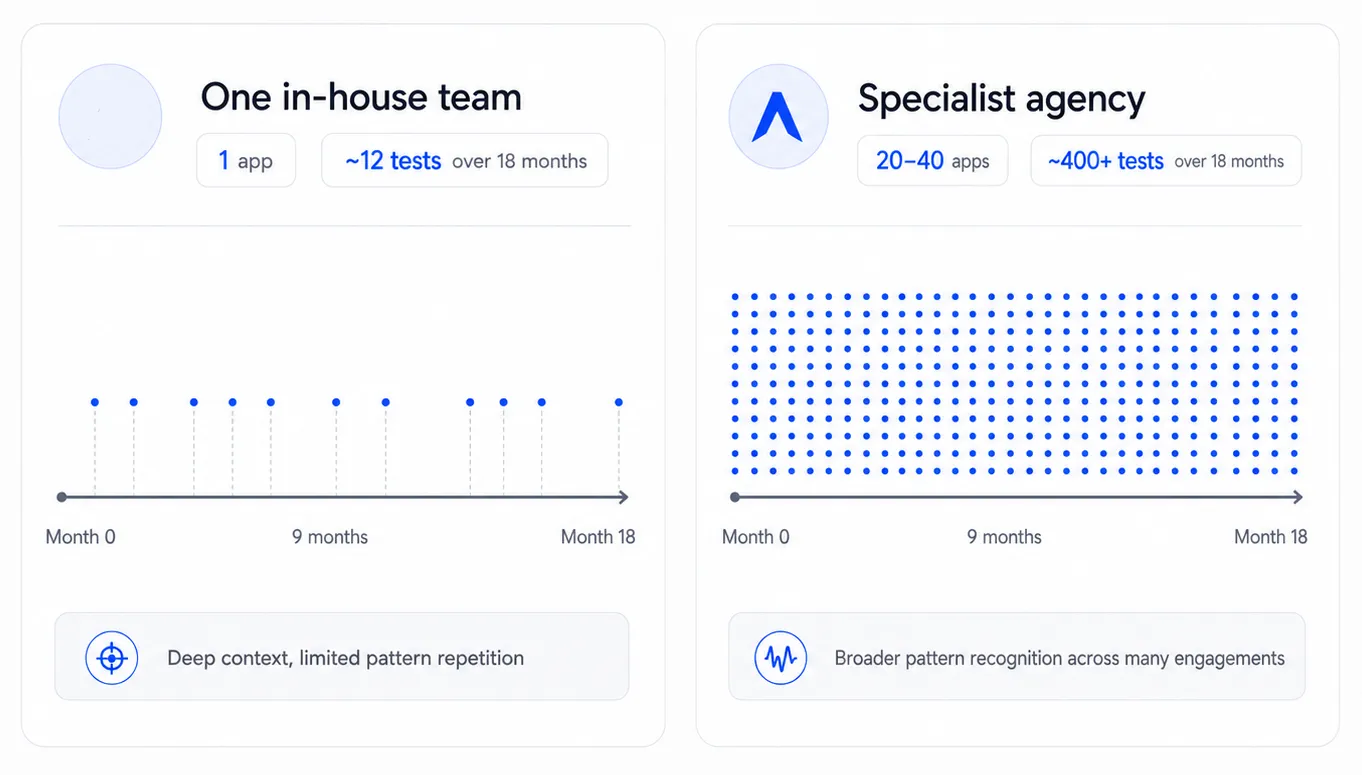
The structural argument is short. An agency running 20–40 client engagements simultaneously sees patterns a single in-house team encounters maybe once every 18 months — and those patterns compound across engagements in a way that single-team experience cannot replicate. The 2026 procurement literature on agency-versus-in-house surfaces this exact framing: an agency working across many clients sees performance patterns, channel shifts, and failure modes that an in-house hire sees once every 18 months. That pattern recognition compounds.
The argument applies even more sharply on the product side than on the paid-media side from which it's most commonly cited, because product surfaces are more bespoke than ad platforms: every app's paywall, every app's onboarding, every app's instrumentation has more idiosyncratic structure than every app's Meta campaign. Mobile growth agencies specifically built around subscription mobile carry cross-pollinated intelligence into every engagement — the same logic transfers from the user acquisition side to the product optimisation side.
3 concrete forms of pattern recognition show up across mid-market subscription engagements.
- Test priors — knowing which paywall, onboarding, or trial mechanic tends to win in subscription mobile before any specific test runs. A team that's seen 50 paywall A/B tests across 25 apps starts a 51st test with priors no in-house team can build inside one product.
- Failure modes — knowing what tends to break in the first 30 days of an engagement before the team even reads the funnel. Instrumentation gaps, sources-of-truth disagreements between Mixpanel and RevenueCat, event taxonomies that aggregate purposes they shouldn't, definitional drift between dashboards. Applica's experiment-history review framework anchors this diagnostic discipline.
- Vertical-specific transfer — knowing what carries from one WellTech app to another, and what definitely doesn't transfer from FinTech to EdTech. The cross-vertical playbook misapplications are some of the most expensive mistakes mid-market apps make.
The structural advantage isn't running more tests — it's knowing where to look first. A senior in-house PM with five years of experience may have run 10–15 tests across one app over the last 18 months. A specialist agency over the same period has run hundreds across dozens of apps. Same hours, different distribution of evidence.
Nemo, a FinTech app, illustrates the dimension concretely. A 4x decrease in cost per first-time deposit (CFD) while scaling a 6-digit monthly UA budget over five months looks like a campaign-structure win on the surface. It worked at the pace it did because cross-client priors on FinTech regulatory-constrained UA already existed — what tends to work, what tends to break, which campaign architectures Meta optimises against deposits cleanly versus installs. The engagement compressed because the diagnostic phase ran on patterns rather than from-scratch hypothesis generation.
How cross-client patterns translate into client decisions
Pattern recognition is inert until it changes a specific decision. The translation works through two concrete mechanisms — compressed diagnostic time and sharper initial hypotheses — and both show up in engagement timelines.
EF Hello, an EdTech app, illustrates the second mechanism. The path to Apple App of the Year 2024 ran through the resolution of major analytics challenges in a competitive EdTech landscape — instrumentation gaps that had been quietly distorting performance reads. The diagnostic phase was compressed because cross-client priors on EdTech analytics failure modes already existed: which events tend to be misnamed, which taxonomies tend to silently aggregate trial conversions with renewal events, which dashboards tend to disagree with each other. The testing programme could compound on top of a foundation that was readable; it couldn't have compounded on instrumentation that wasn't.

Across our portfolio of subscription engagements, we've consistently seen the same structural pattern: source-of-truth misalignment between Mixpanel, RevenueCat, and Stripe (or the equivalent stack) on the same business question — number of paying users, trial-to-paid rate, monthly cohort revenue. Each tool answers a slightly different version of the question, and no one's designated which version is authoritative. Every decision meeting starts with a number argument that's actually a definitional argument in disguise. That pattern is invisible from inside a single engagement; it's clear within 30 days from outside, because it's everywhere.
The compounding mechanism is the part that's easy to underestimate. The agency doesn't have more general talent than the in-house team — it has access to a distribution of cases the in-house team is structurally locked out of. That's the dimension that compounds, and the one procurement-stage buyers most often underestimate when running the agency-versus-in-house spreadsheet.
What are the risks of working with a multi-client agency?
3 risks are real and worth naming honestly. The mitigations are well-understood — contracted, not philosophical.
| Risk | What it looks like in practice | Concrete mitigation |
|---|---|---|
| Data sharing | Patterns travel both ways across the agency's portfolio; sensitive insights or playbooks could surface in adjacent engagements | Contracted confidentiality boundaries; no portfolio-wide sharing of paywall variants, pricing strategies, or competitive intelligence without explicit consent |
| Scope dilution | Account team stretched across too many clients; the breadth-versus-depth trade-off bites when capacity is tight | Named account lead with a documented capacity cap; structured weekly review cadence; written escalation path before the engagement starts |
| Switching costs at exit | Institutional knowledge sits with the agency; transitioning to in-house or another partner risks losing accumulated context | Contracted knowledge-transfer deliverables; documented operating cadence and methodology; structured handoff plan with a named in-house owner |
On data sharing, the mitigation that actually works is structural rather than rhetorical. Pattern recognition across the portfolio is the point of the engagement, but the pattern is not the same as the playbook. An agency can know that paywalls A and B both tend to outperform paywall C in WellTech onboarding without sharing the specific variants, copy, or pricing of any client's actual paywall A. The contracted boundary is on the specific variant; the pattern is the abstracted lesson. Procurement-stage buyers should ask explicitly how that boundary is operationalised.
On scope dilution, the diagnostic is simple. Ask the agency how many active engagements the proposed account lead currently runs, and at what active-engagement count the lead would be over-extended. Account lead capacity is the dimension that determines engagement quality — and it's surfaceable in 30 seconds of discovery-call questioning.
On switching costs, the right move is contracted at the start, not at the end. A partner who can't define what the engagement-end handoff looks like at the start of the engagement is signalling they don't have one.
When this option is the right fit — and when it isn't
The decision resolves cleanly when 3 factors are evaluated honestly: stage, problem type, and team capacity.
Stage. Series A through C, $1–$10 million MRR, is the structural sweet spot. Below that range the engagement economics are heavy relative to the revenue base; above that range the work has often internalised, and the company has the budget for both leadership headcount and specialist depth.
Problem type. Multi-surface bottlenecks — paywall plus onboarding plus retention plus analytics, all needing work in parallel — favour the broadest scope. Single-screen problems favour a freelancer or boutique. When the diagnosis itself is unclear, the broadest scope wins by default, because a diagnostic phase can re-scope toward whichever surface actually moves the business.
Team capacity. An in-house lead already in place is the strongest signal — the agency reports to a named owner, the engagement compounds rather than diluting. A company with no PM at all faces a different dynamic: the agency does more of the strategic work in the absence of an internal owner, which works but doesn't build the internal capability the company will eventually need.
When this option is not the right fit. Pre-product-market-fit (hypothesis still being formed). Enterprise scale, $50 million-plus annual recurring revenue (work has internalised). Single-surface fixes (boutique or freelance is the right scope). Applica's Conversion Rate Optimization engagements open with exactly this scoping question — if a narrower option is the right fit, we say so.
Frequently asked questions
How much does a specialist mobile product growth agency cost in 2026?
Typical retainers run $20,000–$60,000 per month for full-coverage engagements, scaled to scope. The lowest retainer is rarely the lowest total cost — engagements that need re-scoping mid-flight, or produce work that doesn't compound, are expensive at any retainer. The lower end of the band usually buys execution depth on two or three service lines; the upper end usually buys full functional coverage across product, design, analytics, paid UA, and creative, with a senior account lead and a structured operating cadence.
How do you onboard an agency without conflict with an existing in-house PM?
Define ownership boundaries before the engagement starts, in writing, in the contract. Who owns the roadmap? Who owns experiment design? Who owns the data pipeline? Who owns the reporting layer leadership reads on Monday mornings? Settle these in scoping, not in month two when something goes wrong. Most failed hybrid engagements failed because the boundaries were assumed rather than contracted — our companion piece on choosing a product management partner covers the upstream procurement discipline in detail.
What about combining a fractional CPO with an agency?
Increasingly common at the upper end of mid-market. The fractional CPO owns roadmap, prioritisation, and leadership-level decisions; the specialist agency executes on the testing programme and specialist channels. The combination works when the boundaries are explicit and the fractional CPO is a sponsor — not a layer of approval. Done well, this hybrid-of-hybrids carries the cross-portfolio priors of two distinct external sources at once.
Three takeaways
The in-house-versus-outsourced question is settled at mid-market — most run hybrid. The better question is whichexternal source fits which problem.
Each of the 5 sources is structurally good at something specific and bad at something specific. Matching the source to the problem is what makes the spend compound.
Cross-client pattern recognition is the underappreciated structural advantage of specialist agencies — same hours, different distribution of evidence. It compounds in a way that single-team experience cannot.
If you're scoping where the leverage in your specific situation actually sits, the right next step isn't a vendor selection — it's a diagnostic. Applica Agency's Conversion Rate Optimization engagements start with exactly that question, and the honest answer sometimes points away from a full retainer and toward a narrower scope.











