
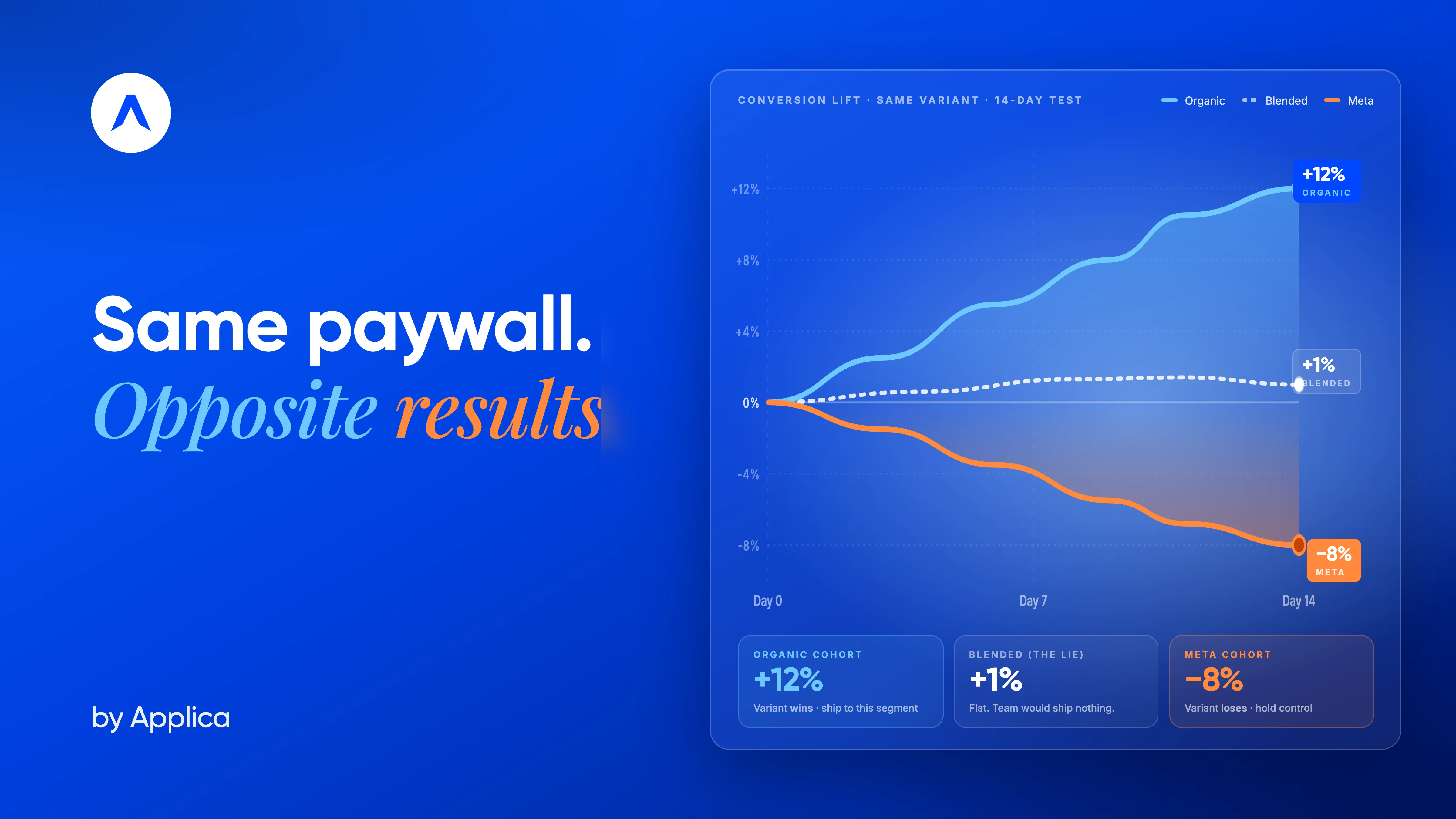
Why the Same Paywall Wins on Organic and Loses on Meta: The Case for Segmented A/B Testing
A subscription team runs a paywall test. Two variants, an even traffic split, clean instrumentation. The result reads +1% on trial-to-paid — flat enough that the experimentation lead flags it as inconclusive and ships nothing. Six weeks of decision capacity, gone.
What the blended readout hid: Meta-acquired users converted -8% on the variant. Organic users converted +12% on the same variant. Two real cohorts moving in opposite directions, averaging out to the appearance of nothing.
This is the modal pattern on cross-channel paywall tests, not an edge case. The same change that compresses anxiety for a cold paid-social cohort can flatten the offer for a warm organic cohort that arrived ready to commit. Most published A/B testing guidance assumes population homogeneity. Subscription mobile is structurally the opposite. At Applica Agency, we've seen the pattern repeat across categories, price points, and channel mixes. The fix isn't a new statistical method — it's an operating system change: stop reading blended numbers as if they describe any real user, and start designing tests for the heterogeneity that already exists in your acquisition mix.
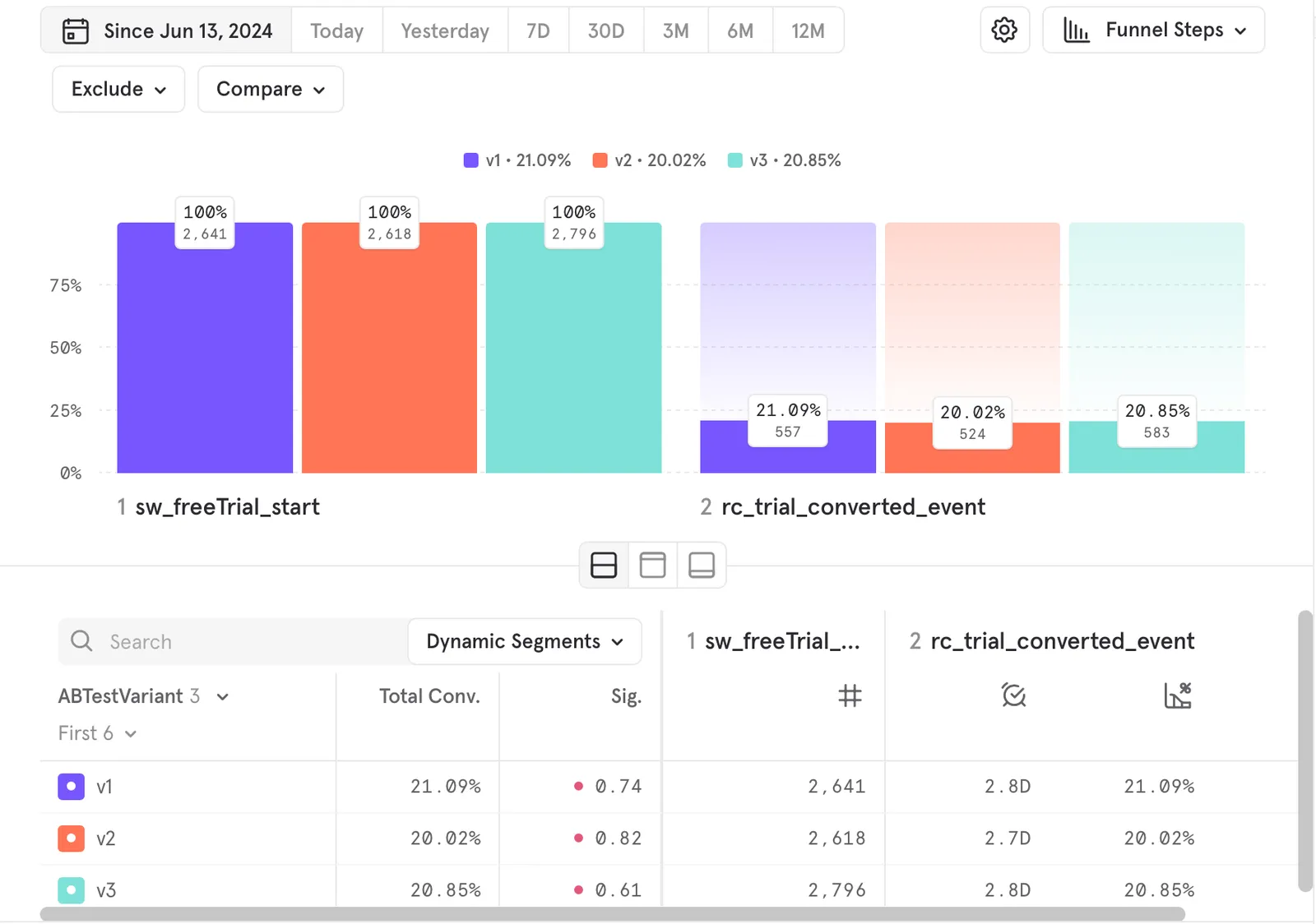
How segment-divergent A/B test results actually look
A typical cross-channel paywall test looks fine in summary view. Total conversions, statistical significance flagged at 95%, lift number sitting near zero. The instinct is to call it inconclusive. The next instinct, on a team that ships fast, is to call it a tie and revert.
Both instincts hide the same problem. Segmented by acquisition source, the same data often shows two cohorts that disagreed sharply — one moving up double digits, the other moving down — and a blended number that represents the weighted disagreement, not a tie.
Heterogeneity at this scale isn't a freak of one bad test. RevenueCat's 2026 State of Subscription Apps report, drawn from more than 115,000 apps and over $16 billion in transactions, documents median Day-35 trial-to-paid conversion at 2.6% in North America, 2% in Western Europe, and 1.4% in India and Southeast Asia — and that's only the regional cut. Channel-level heterogeneity inside a single market is typically larger. The report's wider takeaway underscores the point: the top 10% of apps grew monthly recurring revenue (MRR) by 306% year over year while the median app grew 5.3%. When the population that hits your paywall is that heterogeneous, the assumption that one variant works the same for all of them is the assumption that needs defending — not the alternative.
The reason most teams don't see this in their own data isn't capability. It's defaults. Every major experimentation platform displays the blended readout first, and almost every published A/B testing playbook treats the blended readout as the answer. The segment-level reads are usually one click away. Most teams don't click.
Why do cold and warm traffic convert differently on the same paywall?
A cold paid-social user and a warm organic user arrive at the same paywall carrying different psychological cargo. The cold user was scrolling Instagram or TikTok ninety seconds ago, saw a creative, tapped through curiosity, and landed in your onboarding. Their intent is provisional. Their anxiety is high. Their tolerance for commitment is low.
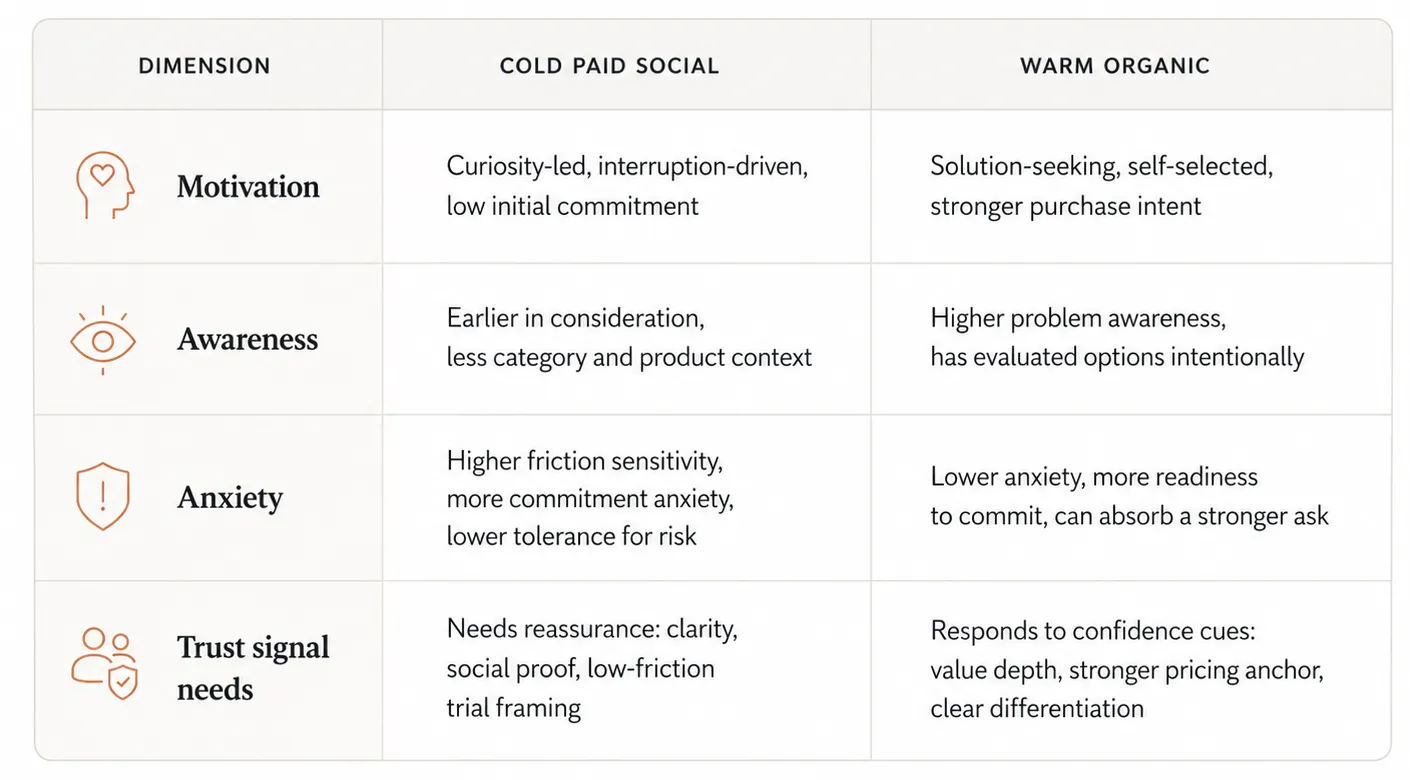
The warm organic user searched for the solution your app provides, evaluated several options on the store, read reviews, and chose your icon deliberately. Their intent is established. Their anxiety is lower. They can absorb a higher commitment threshold — an annual default, a stronger anchor price, a more confident value claim — without flinching. As Adjust's framework on paid versus organic dynamics puts it, the funnel dynamics between paid and organic at the awareness stage are structurally different from those at the conversion stage — and pretending otherwise costs you efficiency in both directions.
This isn't editorial intuition. Heterogeneous treatment effects (HTE) are a named, studied phenomenon in the experimentation literature, with formal methods built specifically because the average treatment effect across a heterogeneous population is often the wrong number to ship on. The Netflix experimentation team's published HTE framework estimates per-segment effects, standardises comparisons across tests, and quantifies the incremental value of personalising over rolling out the global winner. A peer-reviewed paper from Snap's experimentation team makes the structural argument plainly: the most commonly used A/B testing framework is built around Average Treatment Effect, which by construction cannot detect how a feature change impacts users of different countries, devices, or acquisition cohorts.
The practical translation for subscription mobile: a paywall that wins on average can be a clear winner for organic and a clear loser for paid social — or the reverse — and the team shipping the global winner is shipping the loser to whichever segment was the minority in the blended sample.
The structural failure compounds with the validation gate you're already running. Analytics tells you that conversion shifted. The A/B test tells you whether the change caused the shift. But neither tells you the change worked for all users it touched — a question we cover in more depth in our companion piece on the analytics-versus-experimentation distinction. That third question requires segmented analysis on purpose, not blended analysis by default.
The wrong way to read these tests — blended single-number readouts
When two segments move in opposite directions on the same variant, the blended number can land anywhere. It depends on the segment-mix in your sample, the relative conversion baselines of each segment, and any drift in your acquisition mix across the test window. A blended +0.5% might describe a +12 / -10 split. A blended -0.5% can describe the same. Neither describes any real user.
This is Simpson's paradox in production experimentation. The phenomenon — where a trend that holds in every subgroup reverses or disappears when subgroups are aggregated — is well-documented in A/B testing specifically, not just in introductory statistics textbooks. One realistic case walkthrough traces a checkout flow test where the variant wins in every segment and yet loses in aggregate, because mid-test traffic composition shifted and the segments with higher baselines weren't evenly distributed across arms. Shipping the aggregate winner means shipping the version that performs worse for both new and returning visitors.
The cost of reading these tests blended falls into three buckets. Shipping the loser for whichever segment was the minority in your traffic mix, because the majority segment's lift compensated. Killing the winner for both segments, because the directional contradiction made the blend look flat. Burning the decision entirely — calling the test inconclusive and reverting, when the real result was two opposite signals that needed two different responses.
The strategic cost stacks on top. RevenueCat's 2026 data shows subscription growth concentrating sharply at the top of the market — the strongest operators are pulling away from the median. Teams that ship on blended reads are systematically slower at finding the segment-level wins their better-instrumented competitors are already shipping.
How do you A/B test when traffic sources behave differently?
Two operating paths handle this honestly. They aren't interchangeable, and choosing between them is a strategic decision, not a technical one.
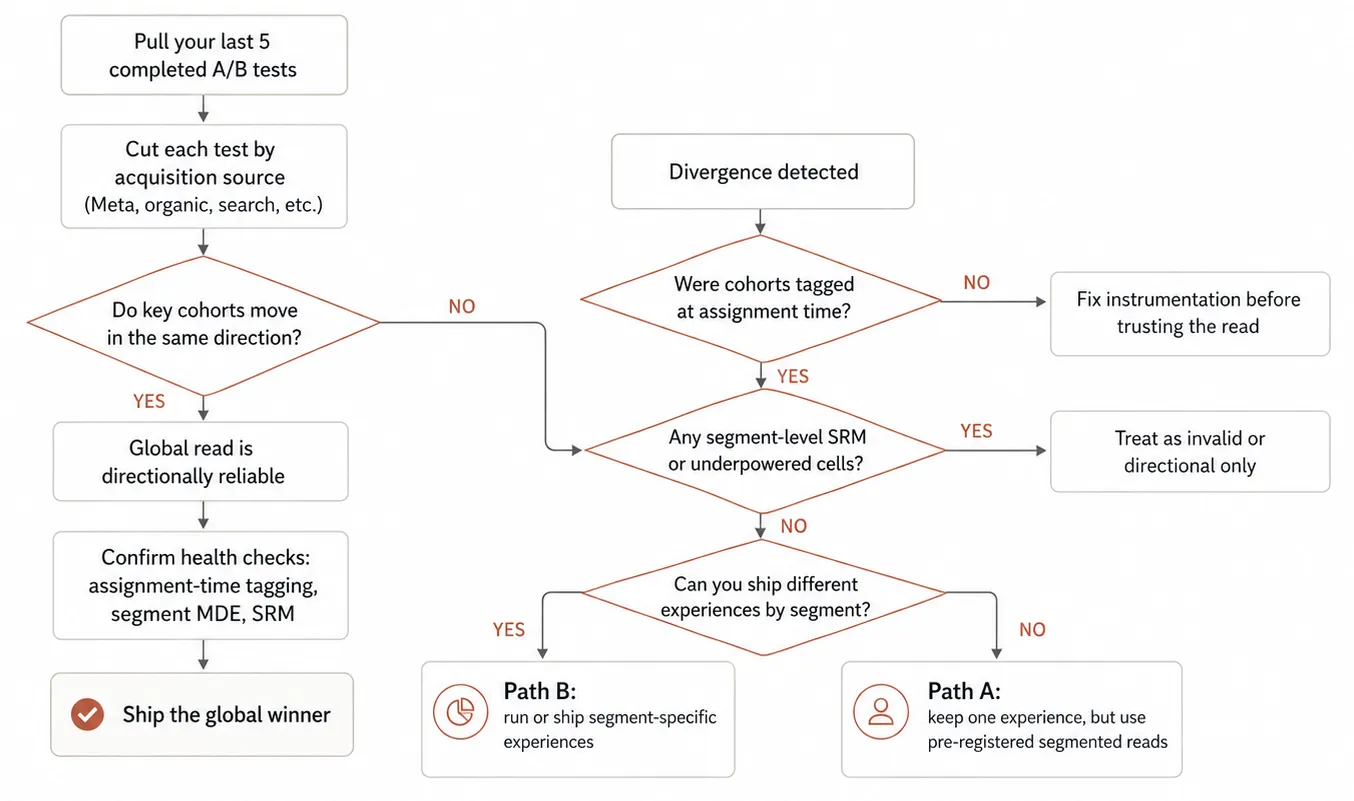
Path A — blended assignment, segment-stratified analysis. Run a standard A/B test with traffic flowing into each variant in normal proportions. Pre-declare the segments you'll cut by — acquisition source at minimum, and ideally one or two more (GEO, device, returning-versus-new). Read the result per segment, not just globally. If segments agree on direction, ship the global winner. If segments diverge, you've found heterogeneity, and the ship decision belongs to a separate discussion.
Path B — parallel separate tests by segment. Run independent tests on each acquisition cohort, with potentially different variant designs per segment. A cold paid-social user may need a different paywall hypothesis than a warm organic user — different headline, different commitment depth, different trust signals — and Path B lets you test those hypotheses directly rather than asking one variant to win across both. The trade-off is sample efficiency: each test needs its own statistical power, which means longer runtimes per segment.
The honest comparison:
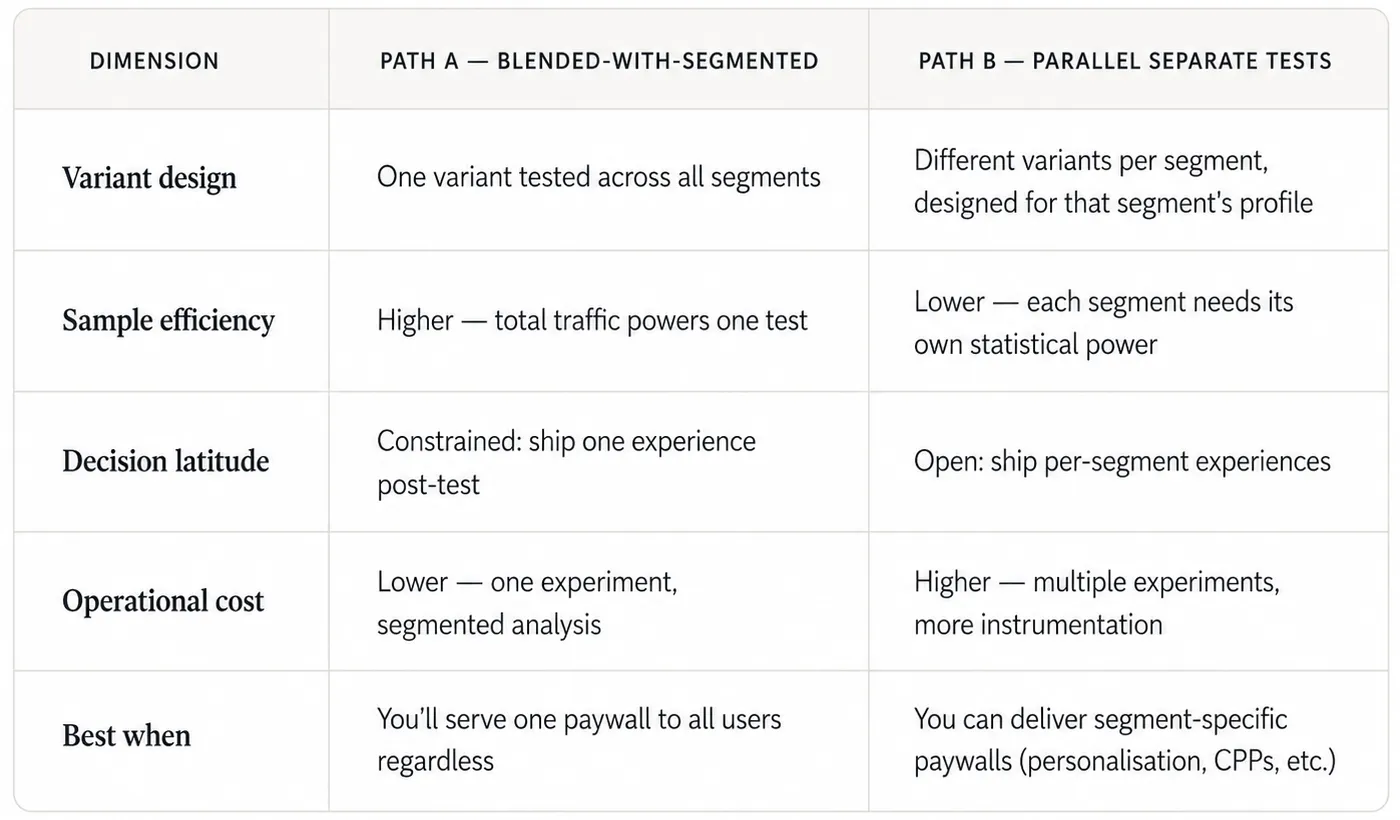
Path A is the correct default for teams whose post-test ship is a single experience. Path B becomes correct the moment you can deliver differentiated experiences — and the 2026 paywall tooling stack increasingly supports it. RevenueCat's 2026 trends data shows hard paywalls converting at a median 10.7% Day-35 trial-to-paid versus 2.1% for freemium — a roughly fivefold gap. The dispersion across paywall types is itself an argument that one paywall design cannot win across heterogeneous demand profiles.
Hypothesis quality is what compresses speed-to-impact, and segment-specific hypotheses are higher-quality than one-size-fits-all hypotheses by construction. We unpack the timeline mechanics of that in our piece on realistic ROI timelines for product optimisation.
What infrastructure do you need to run segmented A/B tests properly?
The infrastructure layer is where most teams fail this quietly. Four pieces matter, and the absence of any one of them turns segmented testing into segmented guessing.
Cohort assignment, not cohort attribution. Tag each user with their acquisition source at assignment time — when they enter the test — not at conversion time. Reading segments by where users converted introduces selection bias: users who didn't convert never tagged. The Applica onboarding experiments analytics guideline treats end-to-end event integrity as the foundation for trustworthy A/B testing, and segment tagging at assignment is part of that foundation.
Per-segment Minimum Detectable Effect (MDE) sizing. Most experimentation platforms compute MDE globally — the smallest lift the test can detect at your chosen power. Per-segment, the MDE is necessarily larger because each segment is a smaller sample. If a global test is powered to detect 5% lift, the per-segment power may only detect 12-15% lift. Plan the test runtime around the segment MDE, not the global one — or accept that segment reads will be directional rather than statistically conclusive.
Sample Ratio Mismatch (SRM) at the segment level. SRM — when the observed assignment ratio differs from the configured ratio — is one of the most under-checked failure modes in production experimentation. Microsoft Research's SRM diagnostic framework names common causes across the assignment, execution, log-processing, and analysis stages, and treats SRM as a gating check before any result analysis. Their finding that SRM occurs in roughly 6% of A/B testsapplies to the global check. The segment-level rate is higher — because assignment biases that are invisible globally, like bot traffic concentrated on one channel or a broken software development kit (SDK) on iOS-from-paid-social, show up clearly at the segment cut.
Variance reduction with CUPED (Controlled-experiment Using Pre-Existing Data). Variance reduction matters more in segmented analysis than in blended analysis, because each segment has a smaller sample and therefore higher variance. CUPED, introduced by Microsoft in 2013 and now standard at Netflix, Booking, Airbnb, and DoorDash, uses pre-experiment user behaviour to control for natural variation and reach significance with smaller samples. For segmented reads on subscription mobile, it's often the difference between a usable per-segment estimate and weeks of additional traffic.
The discipline most teams skip — pre-defined segment-level thresholds
Infrastructure makes segmented analysis possible. Discipline makes it usable.
Pre-registration is the discipline. Before launching the test, write down — and circulate — the analysis plan: which segments you'll cut by, what counts as a winning result per segment, and what action follows each possible outcome. Both Kameleoon's framing on SRM and experiment integrity and Eppo's work on variance-reduction discipline treat pre-registration as the only defence against post-hoc rationalisation, where segment-level reads become a tool for explaining away whatever decision the team wanted to make anyway. Without pre-registration, segmented analysis is just selective storytelling with extra steps.
The decisions to pre-register are concrete. What ship decision follows if both segments agree on direction? Usually: ship the global winner. What follows if one segment wins and another loses? Three honest answers — ship by segment if you can deliver per-segment experiences; ship the larger-traffic winner and document the trade-off; ship neither and design segment-specific variants for the next test. What follows if both segments are flat? Move the hypothesis off the roadmap.
This is the operating system, not the tactic. Applica's A/B testing programme engagements build these decision rules into the experiment roadmap before any variant is designed — because the cost of figuring them out after the result lands is the cost of arguing about the result.
The pre-launch discovery work matters too. Applica's own published thinking on personalising paywall messaging for different user segments treats acquisition source as one of four core segmentation signals, alongside onboarding data, behavioural signals, and demographics. The same segments that drive paywall design in the discovery phase should drive paywall test reads in the validation phase. Treating one without the other is a half-finished operating system.
How do I check if my A/B tests have segment-divergent results?
Pull your last five paywall or onboarding tests. Cut each one by acquisition source — at minimum, paid versus organic. Look at trial conversion, trial-to-paid, and Day-7 retention per segment.
You'll likely find at least one inversion in five — a test that read flat globally and split sharply by source. That's the floor expectation across the portfolios we audit. Higher inversion rates correlate with one of three things: heavier paid-channel mix, larger price points (which amplify cold-versus-warm tolerance differences), or recent acquisition-mix shifts — a Meta campaign ramp, a TikTok pilot, an iOS-organic-search lift. Applica's experiment history review framework walks through the structured version of this exercise. When you scale it past five tests into a quarter of historical experimentation, the structural patterns get easier to see.
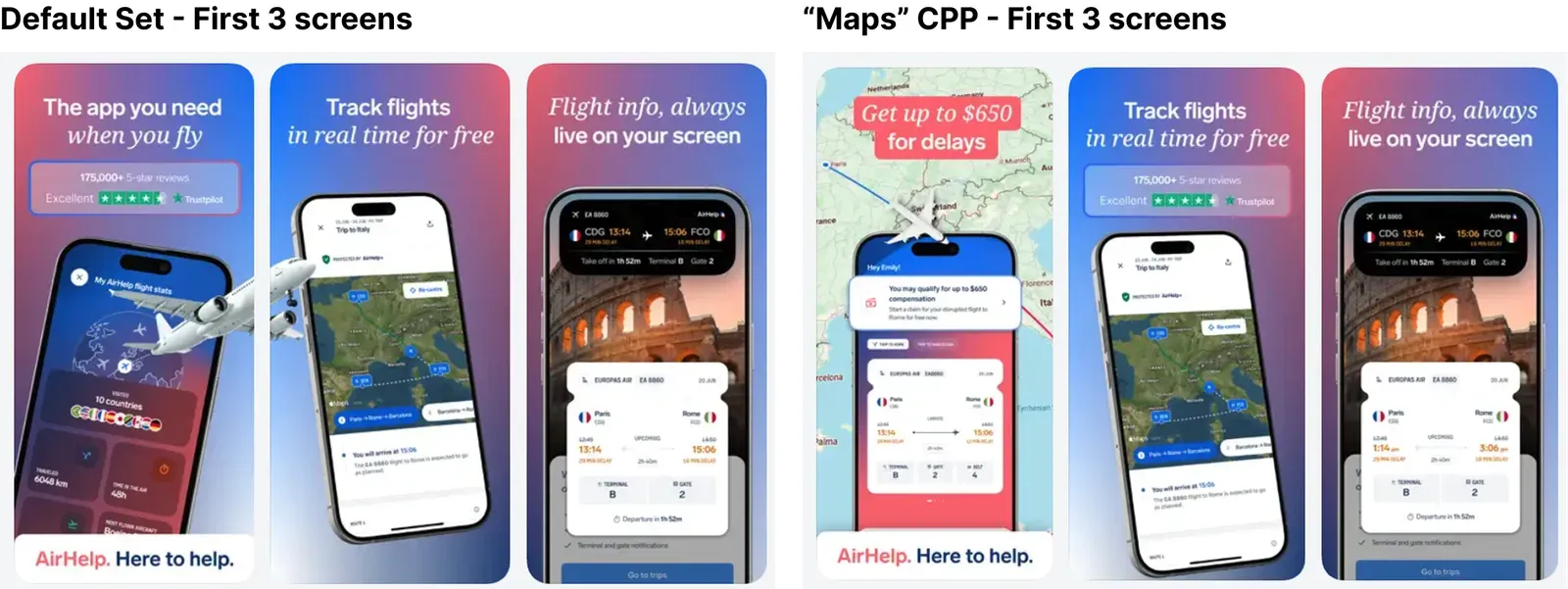
The operationalised version of segmented testing already exists in one channel, and it's worth studying as a model. AirHelp's work on Custom Product Pages (CPPs) for Apple Search Ads (ASA) tested different CPP variants matched to different ASA search intents — segmented experimentation made native to the channel, with performance read per-variant rather than averaged across the cohort. CPPs are what segmentation looks like when you stop fighting heterogeneity and start designing for it.
FAQ
Does this apply at lower traffic volumes? Yes — but segment-level reads need roughly 200–300 conversions per segment for stable estimates. Below that, sequence the tests by segment rather than running in parallel: validate the hypothesis on the highest-traffic segment first, then test on adjacent cohorts once the first read is conclusive.
Is segmented testing the same as paywall personalisation? No. Segmented testing is the validation layer — confirming that a variant works differently across segments. Personalisation is the ship layer — delivering different experiences once you know which variants belong to which segments. You can do the first without committing to the second; the second only works honestly if you've done the first.
What if I only have one acquisition channel? Heterogeneity still appears — by GEO, device, returning-versus-new, day-of-week, app-store category source. The channel cut is the largest single source of variance in most cross-channel apps, but it isn't the only cut worth segmenting on.
Three things to take away
Heterogeneity is the default, not the exception. Subscription mobile users arrive at the paywall carrying different intent, anxiety, and commitment profiles by source — and a single paywall variant cannot win evenly across that distribution.
Blended reads hide winners and losers in equal measure. The structural failure isn't your test design, your platform, or your sample size. It's the default to read aggregate numbers as if they describe any real user.
The fix is operational discipline, not new tooling. Pre-registered segment-level decision rules, assignment-time cohort tagging, per-segment MDE sizing, segment-level SRM checks, and CUPED for variance reduction — the pieces already exist. The discipline of using them together is what's missing.
If your team is shipping decisions on blended reads while running cross-channel acquisition, that's where a structured segmented-experimentation review pays for itself — let's talk: Applica Agency A/B Testing & Data Analysis.











